Identifying adaptive footprints in the presence of demographic uncertainty
Identifying genomic regions shaped by natural selection is a central goal in evolutionary genomics. Existing machine learning methods for this task are typically trained on labeled data simulated according to specific evolutionary scenarios. While effective in controlled settings, these models are limited by their reliance on explicit class labels, detecting only the processes they were trained to recognize. This limitation makes it difficult to interpret predictions for regions shaped by other evolutionary forces, a problem especially acute when analyzing genomes influenced by mixtures of adaptive and demographic factors. One-vs-rest strategies offer a potential alternative but suffer from the complexity of modeling processes as a catch-all “rest” class. Here, we explore positive-unlabeled learning as a flexible framework for detecting adaptive events. This semi-supervised approach permits identification of a target class using only positive labels and an unlabeled background, without requiring explicit modeling of negatives. To assess its utility, we focus on a binary classification setting for detecting selective sweeps against a mixed background of unlabeled sweeps and neutrally evolving regions. We introduce PULSe, a method that trains only on labeled sweep observations while treating remaining data as unlabeled. By avoiding assumptions about background composition, PULSe enables robust sweep discovery in realistic genomic landscapes. We evaluate performance across demographic, adaptive, and confounding contexts, including domain shift from misspecified models, and find that PULSe delivers strong generalizability. Finally, analyzing European and Bengali genomes, we recapitulate known sweep candidates, demonstrating PULSe as a versatile tool for detecting adaptive regions across diverse genomic landscapes.
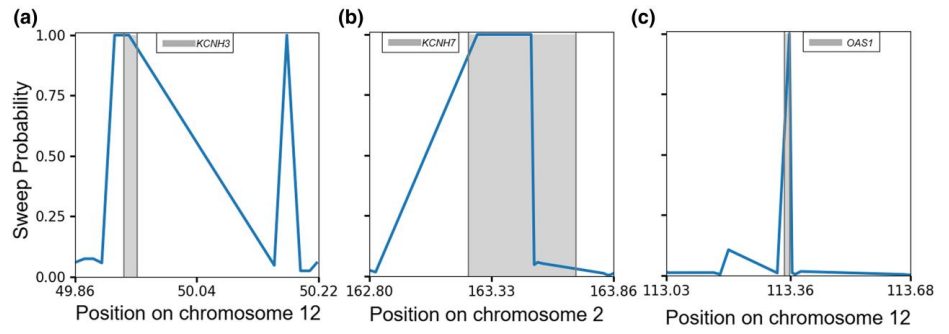
The study is available here.